이 포스트에서는 OpenAI에서 제공하는 STT 모델인 whisper를 사용하여 FastAPI로 작성된 서버로 오디오 파일을 받아 STT 작업을 수행해 본다.
Whisper

Whisper는 Chat-GPT를 만든 OpenAI에서 오픈소스로 공개하는 STT 라이브러리이다.
오픈소스지만 OpenAI에서 만들어서 그런지 상당히 훌륭한 성능을 보여주고 있다.
https://github.com/rtzr/Awesome-Korean-Speech-Recognition
GitHub - rtzr/Awesome-Korean-Speech-Recognition: 한국어 음성인식 STT API 리스트. 각 성능 벤치마크.
한국어 음성인식 STT API 리스트. 각 성능 벤치마크. Contribute to rtzr/Awesome-Korean-Speech-Recognition development by creating an account on GitHub.
github.com
위 출처에서 실행한 벤치마크 결과로는 구글 STT와 비교했을 때 평균적으로 더 높은 성능을 가지고 있다고 한다.
게다가 영어 한정이지만 변환한 텍스트를 영어로 번역하는 기능도 제공하고 있다고.. 는 하지만 깃허브 이슈를 보면 잘 작동하지 않는 것으로 보인다. https://github.com/openai/whisper/discussions/649
또한 최근에 whisper에서 환각 문제가 보고되었지만 아무튼 공짜니까 감사하게 쓰면 된다.
따라서 유료 API를 쓰지 않거나 로컬 환경에서 STT 서버를 구축할 필요가 있을 때, whisper는 아주 매력적인 선택지가 될 것이다. 물론 고성능 모델을 사용하기 위해선 최소 VRAM 8G 이상을 가진 그래픽카드가 필요하다.
Whisper로 사용할 수 있는 모델은 여러 가지가 있고 그중에서 large가 가장 뛰어난 성능을 자랑한다. 하지만 VRAM 10G 이상을 요구해서 진입 장벽이 있는데, 이 포스트를 작성하는 시점에 6G로 돌릴 수 있는 turbo 모델이 등장했으니 부담은 조금 덜해졌다.
공부용으로 사용한다면 자신 컴퓨터 사양에 알맞은 모델을 써서 진행해 보자.
개발환경 준비
Whisper를 사용하기 위해선 준비할 것이 많다.
참고로 공식 문서에서는 파이썬 3.8 ~ 3.11을 지원한다고 적었으므로 꼭 알맞은 버전을 준비하자.
CUDA 설치
Whisper는 파이토치를 사용하는데 이 파이토치를 사용하려면 쿠다를 설치해야 한다. 공식 홈페이지 들어가서 설치해 주자.
이 포스트에서는 파이토치 2.5.1을 사용할 것이므로 그에 맞게 쿠다 11.8을 설치했다.
https://developer.nvidia.com/cuda-11-8-0-download-archive
CUDA Toolkit 11.8 Downloads
developer.nvidia.com
ffmpeg 설치
멀티미디어 인코딩, 디코딩을 지원하는 라이브러리라고 한다.
그런데 윈도우 OS에는 기본으로 설치되어있지 않으므로 설치해야 한다.
이거 설치 안 하고 whisper 쓰려고 하면 오디오 처리를 못하고 에러가 나므로 꼭 먼저 설치해줘야 한다.
윈도우에서는 chocolatey 같은 패키지 매니저나 직접 다운로드하여 환경변수를 설정하는 방법이 있는데 나는 직접 받아서 설정했다.
https://ffmpeg.org/download.html 여기에서 다운로드할 수 있다.
편한 방법을 선택해서 설치하자.
설치가 잘 되었다면 터미널에서 ffmpeg을 쳤을 때 아래와 같이 나올 것이다.
물론 프로젝트에도 파이썬에서 사용할 ffmpeg 라이브러리를 설치해 줘야 쓸 수 있다.
pip install ffmpeg-python프로젝트에 pytorch 설치
Whisper의 공식 문서를 보면 pip으로 바로 설치할 수 있는데 적어도 윈도우에서는 그렇게 바로 따라가면 안 된다.
CUDA용 pytorch를 먼저 설치해 줘야 GPU 사용을 정상적으로 할 수 있었다.
역시 공식 홈페이지를 참고하여 CUDA 버전에 맞는 파이토치를 설치하도록 하자.
PyTorch
pytorch.org
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118프로젝트에 Whisper 설치
드디어 whisper를 설치할 순간이다.
pip install -U openai-whisper
🚨여기까지 단계를 잘 따라오지 않았다면 윈도우에서 각종 에러가 나는 신기한 경험을 할 수 있을 것이다. 꼼꼼하게 확인하도록 하자.🚨
FastAPI 설치
이 포스트에서는 백엔드로 FastAPI 쓴다. 안 보고 다른 거 쓸 수 있으면 그거 하면 된다.
pip install fastapi[standard]API 코드 작성
코드는 다음과 같이 작성했다.
import os
import whisper
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import PlainTextResponse
from tempfile import NamedTemporaryFile
app = FastAPI()
model = whisper.load_model('turbo')
@app.post('/stt')
async def transcript(file: UploadFile = File(...)):
if file.content_type.startswith("audio") is False:
return PlainTextResponse("올바르지 않은 파일 형식입니다.", status_code=400)
file_name = None
with NamedTemporaryFile(delete=False) as temp:
temp.write(await file.read())
temp.seek(0)
file_name = temp.name
try:
stt_result = model.transcribe(file_name)
return PlainTextResponse(f'{stt_result["text"]}', status_code=200)
except Exception as e:
print(e)
finally:
os.remove(file_name)
if __name__ == "__main__":
os.makedirs(temp_dir, exist_ok=True)
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=9886)
turbo 모델을 불러왔고 파일을 처리하는 부분에서 model.transcribe()를 호출하여 STT를 수행하고 그 결과를 PlainTextResponse로 반환하고 있다.
서버를 최초로 실행하면 모델을 다운로드한다.
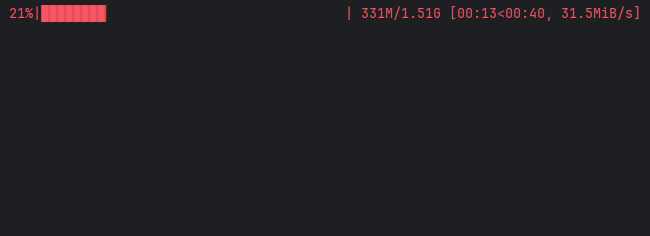
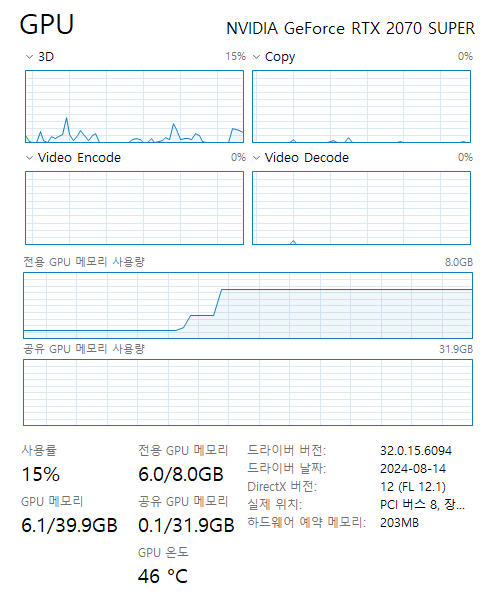
그러면 GPU VRAM의 사용량이 확 튀는 것을 볼 수 있다. readme에 적힌 사양대로 먹는다.
이제 음성을 post 해서 결과를 확인해 보자. 대충 게임 대사를 녹화했다.

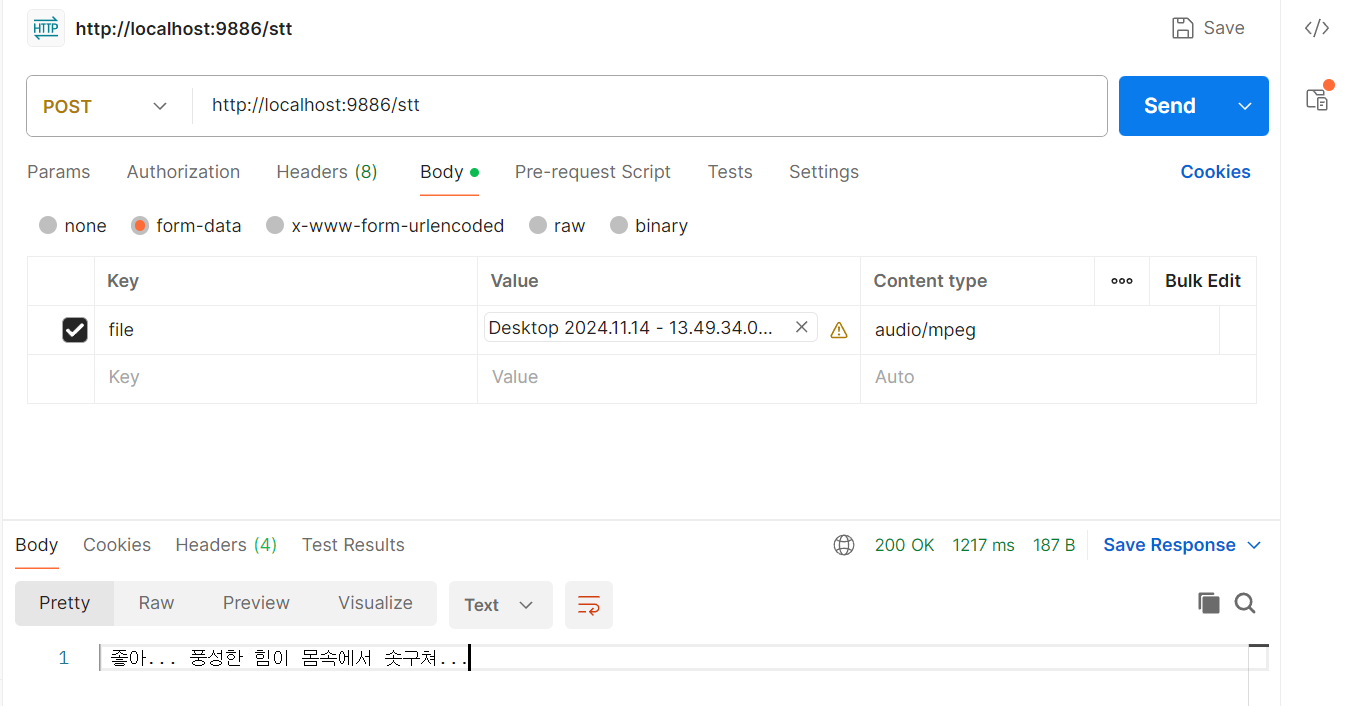
아주 잘된다.
이렇게 OpenAI에서 제공하는 whisper로 STT를 수행하는 API를 개발해 봤다.
오픈소스로 제공되고 있는 만큼 비용 면에서 부담 없이 이용할 수 있을 것이다.
'Python > FastAPI' 카테고리의 다른 글
| 간단한 웹소켓 부하 테스트 비교 FastAPI vs Golang (2) | 2024.12.15 |
|---|---|
| [FastAPI] 웹소켓을 다룰 때 주의점 - 공식 예제 개선하기 (1) | 2024.12.03 |
| FastAPI 서버와 다양한 서비스 비동기 처리하기 (0) | 2024.11.12 |


